Case Study
Concept optimization for Google Search

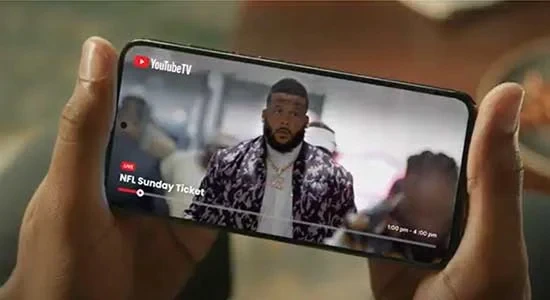
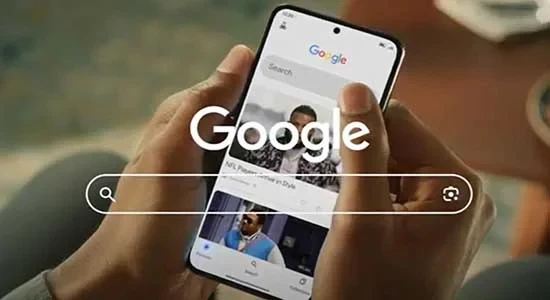

Product interactions were key to the concepts success and driving users understanding.


Tag line “New ways to search” needed to be integrated with more impactful scenes.


Less recalled scenes could by optimized (the fashion items used to showcase Google Lens had low appeal) or removed altogether for short form creative formats, such as video bumper ads and social.